As we know in classification problem, we deal with unlabeled dataset. Unlabeled data means we don't have enough information about the dataset. In this type of problems we have to make cluster with similar type of values(data).
We need an algorithm that can be automatically grouped the data into coherent subset and these groups are known as clusters.
What is k-mean cluster ?
It is an algorithm that is use for classification problem for grouping or clustering of coherent data points. It is divided into two steps.
1. Assignment of centriods.
2. Movement of centriods.
where centriods are the random points or dataset from given dataset.

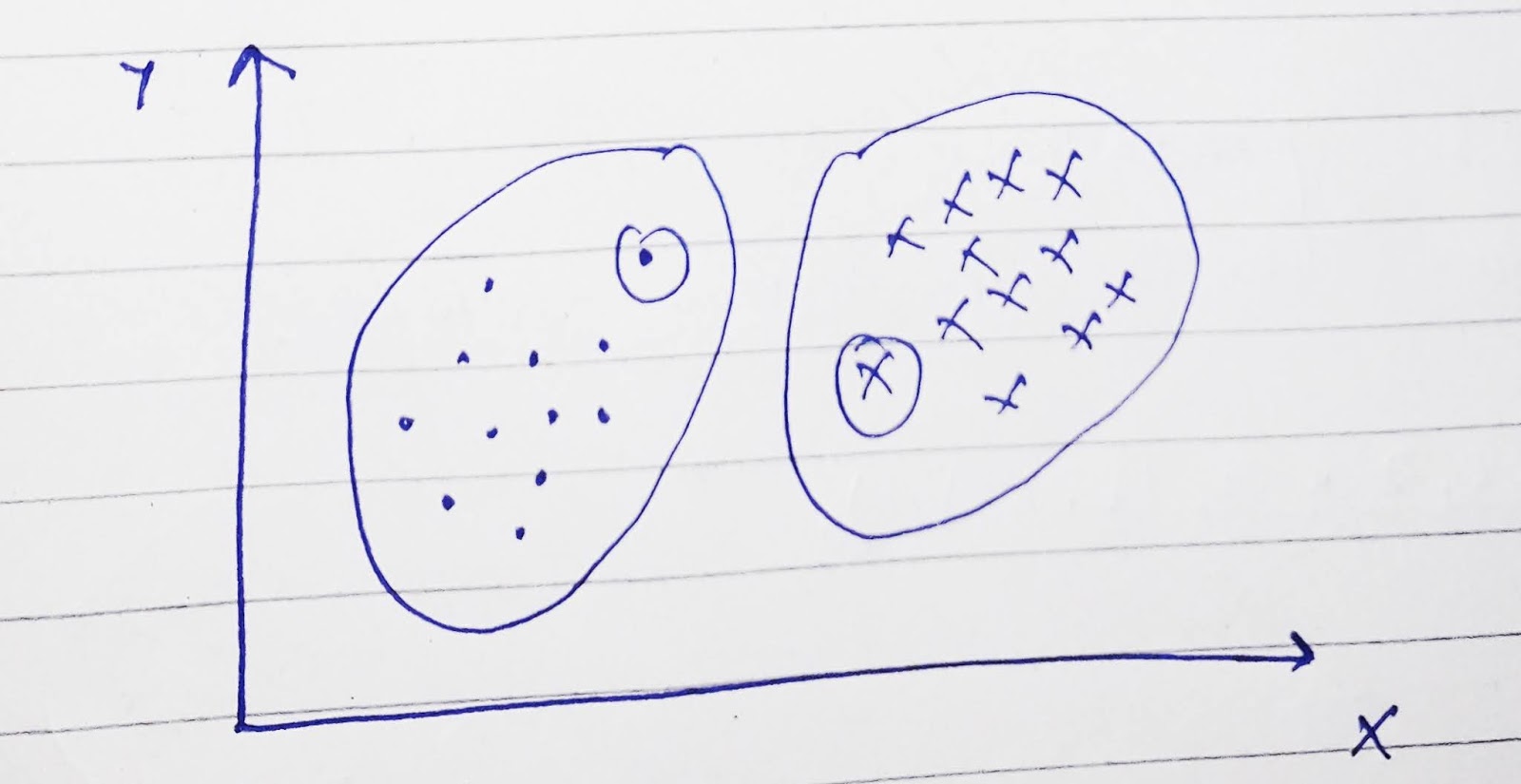
Suppose we have unlabeled dataset in this visualization and our task is to grouped data into coherent cluster.
first of all we select two random points that is known as cluster as shown in figure.
after then we apply euclidean distance formula that is
√(Xo - Xc)^2+ (Yo-Yc)^2
where
Xo = observed value
Xc = centriod value
Yo = oberved value
Yc = centriod value , here all values is in the form of x,y pair because every point in figure is in two dimension.
We calculate values for every data point and put that value( data point) with minimum valued cluster as we take initially.
Replace that cluster value with new cluster value by mean of recently got value and initially taking value.
This algorithm is repeatedly work so after number of iterations we will get following clusters.
This two circle (clusters) will get after number of iterations and these clusters will be coherent groups.
Algorithm:
Input :-
k ( number of clusters , it can be one, two, three and so on... )
training set ( x1, x2 ,x3.......data points)
for i=1 to m
c(i) = index (from 1 to k) of cluster centriod closest to x(i)
for k=1 to K
𝜇k = average of points assign to cluster k.
suppose we have four cluster then
𝜇k = (𝜇1 + 𝜇2 + 𝜇3 + 𝜇4)/4
If in any case that centriod don't have any points, we just eliminate that centriod.
Why use k - mean cluster ?
k - mean clustering algorithm is one of the most popular algorithm for solving classification problem and it is also easy to implement as it use only two formulas euclidean distance and normal mean.
This algorithm is also used for solving non separated clusters problem.
suppose we have a large data set of height and width. our task is to separate small, ,medium and large size shirts from that data points. This problem can be solved with the help of k - mean cluster algorithm.
So this is all about k - mean cluster algorithm.
If you have any query, just drop a comment.
Connect with our Data Science community -
www.instagram.com/datasciencewithkp27
Thank You.




Good post😊
ReplyDelete👌👌
ReplyDelete